Managing vast volumes of data remains a headache concerning performance, dependability, and scalability in the age of big data. An open-source table format, Apache Iceberg, aims to solve crucial problems with a data lake’s architecture.
This document discusses what Apache Iceberg is, its features alongside benefits, its architecture, and its comparison with Delta Lake and Hudi. In addition, we will go over actual use-case scenarios and cover best practices.
What is Apache Iceberg?
Managing vast datasets stored in data lakes can be done with an open-source table format called Apache Iceberg. It supports ACID transactions, schema and time travel, as well as partition evolution making It well-suited for modern data lakehouse architectures.
Core Features of Apache Iceberg
ACID Compliant – Guarantees full data integrity (with sub-parts being atomic), consistency, isolation, and durability.
Schema Evolution – Changes to the structure of the data are implemented without breaking existing queries.
Time Travel – Historical versions of the data can be queried (point-in-time recovery).
Partition Evolution – Dynamically set partitions without needing to rewrite data.
Optimized Metadata – Query planning can be done faster with a multi-level metadata structure.
Multi-Engine Support – Compatible with Spark, Flink, Trino, Presto, among others.
What are the main reasons to leverage Apache Iceberg?
Some of the lake data challenges (e.g. raw HDFS or S3) include the following:
- Absence of ACID transactions (accompanied by dirty reading and writing).
- Lack of strict schema enforcement (resulting in inconsistency).
- Languid metadata operations (giving rise to slow query performance).
The flat file storage system offered by Apache Iceberg takes care of the issues listed above by:
- Providing consistency for transactions (ensuring no partial writes).
- Allowing evolution of schemas without downtime.
- Facilitating improved query performance via smart metadata management.
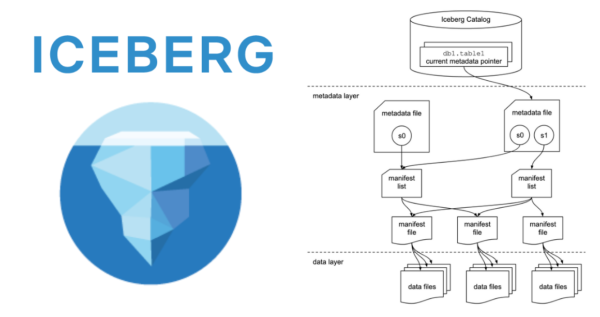
Understanding the structure of an architecture helps in knowing its components. Therefore, here are the layers forming the architecture of Apache Iceberg.
The architecture icebergs is composed of:
- Catalog Layer
- Houses table metadata (current schema, partition layout).
- Facilitates integration with Hive Metastore, AWS Glue and Nessie.
- Metadata Layer
- Metadata Files (JSON) – Contains table snapshots with schemas and partition specs.
- Manifest Lists – Foremost index of the manifest files for the purpose of fast scan planning.
- Manifest Files – Contain data files and their statistics.
- Data Layer
- Contains actual data files (Parquet, Avro, ORC) with the cloud storage (S3, ADLS, GCS).
Diagram of Apache Iceberg Architecture (Source: Apache Iceberg Official Docs)
How Apache Iceberg Works
Write Path With every write, new data is updated in the form of files in cloud storage. Metadata is updated with a new snapshot. All transactions are atomic driven meaning either fully performed or reverted.
Read Path Queries automatically read from the latest snapshot. Time travel can be employed in querying past versions.
Compaction & Cleanup
Expire Snapshots – Cleans obsolete snapshots to reclaim available space.
Rewrite Data Files – Merger small files to improve them.
Apache Iceberg vs Delta Lake vs Hudi
Feature Apache Iceberg Delta Lake Apache Hudi
ACID Support ✅ Yes ✅ Yes ✅ Yes
Time Travel ✅ Yes ✅ Yes ✅ Yes
Schema Evolution ✅ Safe ✅ Safe ❌ Limited
Partition Evolution ✅ Yes ❌ No ❌ No
Multi-Engine Support ✅ Spark, Flink, Trino ✅ Spark-only ✅ Spark, Flink
Metadata Scalability ✅ Optimized ⚠️ Good ⚠️ Moderate
Why Choose Iceberg?
Best for multi-engine workloads (Spark, Flink, Trino).
Exceptional partition evolution and schema modification.
Metadata management is more Delta/Hudi scalable.
Real-World Use Cases
- Data Lakehouse Modernization
Iceberg helps driven Data Lakes for companies like Netflix, Apple, and Adobe who want to replace the traditional Hive tables with scalable ACID-backed lakehouse.
- Machine Learning & Analytics
Reproducible ML time travel enables training datasets.
Evolving feature stores are supported by schema modification.
- GDPR & Compliance
Row-level changes along with selective data removal update compliances for privacy-sensitive legislations.
Data alteration audit logging is managed through snapshots.
Using Apache Iceberg for the First Time
Step 1: Install the Required Tools
bash
Copy
For Spark users
spark-shell –packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.3.0
Step 2: Set Up an Iceberg Table
python
Copy
PySpark Example
df.writeTo(“nyc.taxis”).using(“iceberg”).create()
Step 3: Retrieve Data Using The Time Travel Feature
sql
Copy
— SQL (Trino/ Presto)
SELECT * FROM nyc.taxis FOR VERSION AS OF 12345;
Step 4: Improve How Efficient the System Is
sql
Copy
— Condense numerous small files
CALL system.rewritedatafiles(‘nyc.taxis’);
Apache Iceberg’s Most Important Features
Use Partitioning Wisely.
Don’t overdo it by creating too many partitions (i.e., hourly partitions can negatively impact performance).
Periodical Maintenance Tasks.
Schedule periodic runs for expiresnapshots() and rewritedata_files() to maintain system upkeep . Encourage Caching.
Cache metadata in Nessie or AWS Glue for faster query processing.
Observe System Performance.
Monitor performance closely by checking scan planning time along with file size.
Common Questions About Apache Iceberg
- Is Iceberg a storage format?
No, it’s a table format that manages metadata on top of Parquet/AVRO files.
- Does Iceberg replace Delta Lake?
Not necessarily—Iceberg is better for multi-engine setups, while Delta Lake is tightly integrated with Spark.
- Can I migrate from Hive to Iceberg?
Yes! Iceberg supports Hive metastore integration for easy migration.
- How does Iceberg handle deletes?
Via soft deletes (marking rows) or hard deletes (rewriting files).
- What engines support Iceberg?
Spark, Flink, Trino, Presto, and more.
Final Thoughts:
Apache Iceberg is revolutionizing the data lake landscape into scalable,ACID-compliant lakehouses. It also resolves significant challenges in managing big data with its time travel, schema evolution functionalities and its support for multiple engines.
Summary of Important Points:
Use Iceberg for ACID transactions and schema evolution.
Best suited for analytics through multiple engines such as Spark, Flink and Trino.
Metadata scalability is superior to Delta Lake/Hudi.
Eager to take up Iceberg? Start off with Spark or Trino and unlock its full potential now!